多模式串匹配之AC自动机算法(Aho-Corasick算法)简介与C语言程序实现源码参考
- 存储安全
- 2011-03-23
- 32129热度
- 19评论
一、概述
AC自动机算法全称Aho-Corasick算法,是一种字符串多模式匹配算法。该算法在1975年产生于贝尔实验室,是著名的多模匹配算法之一。AC算法用于在一段文本中查找多个模式字符串,即给你很多字符串,再给你一段文本,让你在文本中找这些串是否出现过,出现过多少次,分别在哪里出现。
该算法应用有限自动机巧妙地将字符比较转化为了状态转移。此算法有两个特点,一个是扫描文本时完全不需要回溯,另一个是时间复杂度为O(n),时间复杂度与关键字的数目和长度无关,但所需时间和文本长度以及所有关键字的总长度成正比。
AC算法有三个主要步骤,一个是字典树tire的构造,一个是搜索路径的确定(即构造失败指针),还有就是模式匹配过程。
学习AC自动机算法之前,最好先熟悉KMP算法,因为KMP算法与字典树tire的构造很是类似。KMP算法是一种经典的单字符串匹配算法。
二、AC算法思想
AC算法思想:用多模式串建立一个确定性的树形有限状态机,以主串作为该有限状态机的输入,使状态机进行状态的转换,当到达某些特定的状态时,说明发生模式匹配。
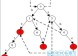
下图是多模式he/ she/ his /hers构成的一个确定性有限状态机,做几点说明:

图2.1
1、 该状态机优先按照实线标注的状态转换路径进行转换,当所有实线标注的状态转换路径条件不能满足时,按照虚线的状态转换路径进行状态转换。如:状态0时,当输入h,则转换到状态1;输入s,则转换到状态3;否则转换到状态0。
2、 匹配过程如下:从状态0开始进行状态转换,主串作为输入。如主串为:ushers,状态转换的过程是这样的:

图2.2
3、 当状态转移到2,5,7,9等红色状态点时,说明发生了模式匹配。
如主串为:ushers,则在状态5、2、9等状态时发生模式匹配,匹配的模 式串有she、he、hers。
定义:
在预处理阶段,AC自动机算法建立了三个函数,转向函数goto,失效函数failure和输出函数output,由此构造了一个树型有限自动机。
转向函数,指的是一种状态之间的转向关系。g(pre, x)=next:状态pre在输入一个字符x后转换为状态next(上图中的实线部分)。如果在模式串中不存在这样的转换,则next=failstate。
失效函数,指的也是状态和状态之间一种转向关系。f(per)=next:是在比较失配的情况下使用的转换关系。在构造转向函数时,把不存在的转换用failstate表示,但是failstate不是一个具体的状态,状态机转换转换到failstate状态的时候就不知道该往哪转了。所以就要在状态机中找到一个有意义的状态代替failstate,当出现failstate状态时,自动切换到那个状态。
这个状态节点应该具有这样的特征:从这个状态节点向上直到树根节点(状态0)所经历的输入字符,和从产生failstate状态的那个状态节点向上所经历的输入字符串完全相同。而且这个状态节点,是所有具备这些条件的节点中深度最大的那个节点。如果不存在满足条件的状态节点,则失效函数为0。
累死了。举例子说吧,对状态9输入任何一个字符都会产生failstate状态,需要失效函数。状态3向上到状态0经过的输入字符串为s;而由状态9向上的输入字符串为sreh。字符串s相同,并且状态3是满足此条件的唯一节点,则
f(9)=3。
说来说去,失效函数就是要干这么件事儿:

图2.3
意思就是说,在比较模式串1发生失配时,找一个模式串2,使得P2[0...j-1] = P1[i-j+1...i]。然后继续比较模式串2。看上面那个图,想起点儿什么东西没有?对了,是KMP算法。有人说AC算法就是KMP算法在多模式匹配情况下的扩展。
输出函数,指的是状态和模式串之间的一种关系。output(i)={P},表示当状态机到达状态i时,模式串集合{P}中的所有模式串可能已经完成匹配。
例:
模式串为:he/ she/ hers/ his 时,如图2.4所示。
转向函数:

图2.4
失效函数:

图2.5
输出函数:

图2.6
三、字典树tire的构造
这个比较好理解,就是把要匹配的一些字符串添加到树结构中去。树边就是单词中的字符,单词中最后一个字符的连接节点添加标志,以表示改节点路径包含1个字典中的字符串,搜索到此节点就表示找到了字典中的某个单词,可以直接输出。
Trie是一个树形结构的状态装换图,从一个结点到它的各个子结点的边上有不同的标号。Trie的叶子结点表示识别到的关键字。
当我们的模式串在Tire上进行匹配时,如果与当前节点的关键字不能继续匹配的时候,就应该去当前节点的失败指针所指向的节点继续进行匹配。
例子:某字典P={he,she,his,hers}对应的字典树如下图:

图3.1
图中有数字的节点到根节点的路劲正好对应字典中的字符串,数字表述单词在字典中的顺序,也可以是其他标志。
四、搜索路径的确定
我的理解是:利用后缀字符串来确定。后缀字符串就是某个字符串的后面的一部分。比如abcde的后缀字符串有bcde,cde,de和e。
假定目标字符串为ushers,字典为上图(图1)所示。
搜索过程目标字符串指针指向的字符和字典中的字符会有以下几种情况:
a. 当前字符匹配。表示从当前节点沿着树边有一条路径可以到达目标字符,此时只需沿该路径走向下一个节点继续匹配即可,目标字符串指针移向下个字符继续匹配;
如:当指针指到s处,此时字典树指针处于根,要从根到s处,可以看到图中有一条从根经s连接到的节点,因此字典树节点指针指向此节点,目标字符串指针移动到下一字符h继续匹配;显然当前节点有一条经h连接到的节点,于是重复操作到有数字标志的节点2处,表示已找到,该匹配字符串就是"she",输出该字符串的位置后,目标字符串指针增1指向"r",字典指针指向数字2节点,进行下次匹配。
b. 当前字符无匹配。表示当前节点的任何一条边都无法达到要匹配的字符,此时不能沿现有路径前进,只能回溯,回溯到存在的最长的后缀字符串处,如果没有任何后缀字符串匹配则回溯到树根处。然后从当前回溯节点判断是否可以到达目标字符串字符。
如:接上,由于数字2节点无经"r"的连接,因此回溯,she的后缀字符串he在字典树中,因此字典树指针指向带有数字1的标志节点,由于带有标志,直接输出该节点"HE"(存疑,很多文章没有提到此处需要输出,正常路径移动的字典指针节点要判断是否可以输出,那么由回溯路径改变的字典指针指向的节点要不要判断是否输出?),然后从数字1节点判断是否有经"r"到下一节点的路径,显然图中有。因此字典树节点指向下一节点,重复以上操作,最后找到"hers",此时匹配搜索也结束了。
以上两种情况直到目标字符串指针直到末尾结束匹配。在匹配过程中遇到有标志的节点说明找到了字典中的某个词,可以直接输出。
输出说明:
每次目标串指针移动前都需要判断当前节点是否可以输出,并递归的判断当前节点回溯路径上的节点是否可以输出(其实就是判断所有后缀字符串,she匹配时,其后缀he也会匹配,即使she不匹配,其后缀he也可能匹配,因此需递归判断后缀字符串),直到树根结束递归。
由于固定字典的字符串的后缀字符串都是已知的,因此可以在字典树结构中存储匹配失败的路径方向,因此只要字典树构造完毕,就可以根据字典树的路径进行匹配了,效率非常快。以上就是我对该算法的全部过程的理解,疏漏之处在所难免。
附录:
附1:
含匹配失败的情况的路径选择的字典树,实线表示匹配成功的正常路径,虚线表示失败的回溯路径
 图 附1.1
图 附1.1附2:AC算法的伪代码实现描述
T为目标字符串,长度为m,q为字典树的节点指针,g函数返回从节点q经过路径T到达的下一节点指针,f函数返回节点q的回溯节点指针。flag判断节点是否为标志节点
q := 0; // initial state (root)
for i := 1 to m do
while g(q,T) = NULL do
q := f(q); // 回溯
q := g(q,T); // 前进
node:=q;
while(node!=root){
if flag(node) exist ; then print i, out(node);
node = f(node); //查找回溯节点
}
end for;
附3:
一个简单的AC算法实现源码示例参考:
/*
程序说明:多模式串匹配的AC自动机算法
自动机算法可以参考《柔性字符串匹配》里的相应章节,讲的很清楚
*/
#include <stdio.h>
#include <string.h>
const int MAXQ = 500000+10;
const int MAXN = 1000000+10;
const int MAXK = 26; //自动机里字符集的大小
struct TrieNode
{
TrieNode* fail;
TrieNode* next[MAXK];
bool danger; //该节点是否为某模式串的终结点
int cnt; //以该节点为终结点的模式串个数
TrieNode()
{
fail = NULL;
memset(next, NULL, sizeof(next));
danger = false;
cnt = 0;
}
}*que[MAXQ], *root;
//文本字符串
char msg[MAXN];
int N;
void TrieInsert(char *s)
{
int i = 0;
TrieNode *ptr = root;
while(s)
{
int idx = s-'a';
if(ptr->next[idx] == NULL)
ptr->next[idx] = new TrieNode();
ptr = ptr->next[idx];
i++;
}
ptr->danger = true;
ptr->cnt++;
}
void Init()
{
int i;
char s[100];
root = new TrieNode();
printf("输入模式串数量:");
scanf("%d", &N);
for(i = 0; i < N; i++)
{
printf("输入第%d个模式串(共%d个):",i,N);
scanf("%s", s);
TrieInsert(s);
}
}
void Build_AC_Automation()
{
int rear = 1, front = 0, i;
que[0] = root;
root->fail = NULL;
while(rear != front)
{
TrieNode *cur = que[front++];
for(i = 0; i < 26; i++)
if(cur->next != NULL)
{
if(cur == root)
cur->next->fail = root;
else
{
TrieNode *ptr = cur->fail;
while(ptr != NULL)
{
if(ptr->next != NULL)
{
cur->next->fail = ptr->next;
if(ptr->next->danger == true)
cur->next->danger = true;
break;
}
ptr = ptr->fail;
}
if(ptr == NULL) cur->next->fail = root;
}
que[rear++] = cur->next;
}
}
}
int AC_Search()
{
int i = 0, ans = 0;
TrieNode *ptr = root;
while(msg)
{
int idx = msg-'a';
while(ptr->next[idx] == NULL && ptr != root) ptr = ptr->fail;
ptr = ptr->next[idx];
if(ptr == NULL) ptr = root;
TrieNode *tmp = ptr;
while(tmp != NULL )&& tmp->cnt != -1)
{
ans += tmp->cnt; //统计文本中出现过的不同模式串数量
tmp->cnt = -1;//对于每个模式串的出现只计算一次,如统计所有出现则应注释该行
tmp = tmp->fail;
}
i++;
}
return ans;
}
int main()
{
int T;
printf("输入测试次数:");
scanf("%d", &T);
while(T--)
{
Init();
Build_AC_Automation();
//文本
printf("输入匹配文本:");
scanf("%s", msg);
printf("%dn", AC_Search());
}
getchar();
return 0;
}
下载:
摘自snort的AC算法源码实现等资料下载: 点击下载此文件
点击下载此文件
点击下载此文件以上内容整理自网络素材,部分解释为个人理解添加或修正。该整理资料必有众多不足,欢迎留言讨论,更多AC算法相关的资料可留下联系方式索取。


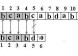
我编译运行了一下,如果模式串为"he,his",目标串为"hesshehis",程序也只识别出两个,就是he和his,其中一个he被忽略了,求解?
这个有点小众,看不大明白
虽然学过点C
顶部的导航似乎有些问题啊……
呵呵,还不错,灰常支持了。。
我也要弄一个你那样的英语显示,正在准备中,[face_49]
学习了~
不懂,围一下
太专业了,我就纯粹支持吧,看不懂
呵呵,看了很有当年学数据结构的感觉哦。。嘿嘿。不错。得好好了解下哦。
这种算法,俺看起来,一点都不头疼,因为俺一点都看不懂^_^ 虽然俺是学网络工程出身的,单页只是半路出家,连编程语言都不会,只会个HTML语言,呵呵,让博主见笑了。
好多函数,想起我的数学,不过后面就看不懂代码了
过来学习了 [face_11]
各种算法让我异常头痛。。。
一打开页面,那2个广告比较显眼~
来看看博主,学习下!
好吧,我承认我看不懂!
需要慢慢研究。
网站风格很清新
这是神马啊?