KMP(Knuth-Morris-Pratt)字符串模式匹配算法解析及C语言实现参考源码
- 存储安全
- 2011-02-08
- 8339热度
- 3评论
字符串模式匹配算法,通俗点说,就是一种在一个字符串中定位另一个串的高效算法。KMP(Knuth-Morris-Pratt)算法是一种基于前缀搜索的方法。简单匹配算法的时间复杂度为O(m*n);KMP匹配算法在搜索阶段的最坏时间复杂度和平均时间复杂度都是O(n),在预处理阶段的时间复杂度是O(m),所以它的时间复杂度为O(m+n)。
一.BF算法:简单匹配算法
先来看一个简单匹配算法的函数:
[code lang=cpp]
int Index_BF ( char S [ ], char T [ ], int pos ) {
/* 若串 S 中从第pos(S 的下标0≤pos<StrLength(S))个字符
起存在和串 T 相同的子串,则称匹配成功,返回第一个
这样的子串在串 S 中的下标,否则返回 -1 */
int i = pos, j = 0;
while ( S[i+j] != ''&& T[j] != '')
if ( S[i+j] == T[j] )
j ++; // 继续比较后一字符
else {
i ++; j = 0; // 重新开始新的一轮匹配
}
if ( T[j] == '')
return i; // 匹配成功 返回下标
else
return -1; // 串S中(第pos个字符起)不存在和串T相同的子串
} // Index_BF
[/code]
此算法的思想是直截了当的:将主串S中某个位置i起始的子串和模式串T相比较。即从 j=0 起比较 S[i+j] 与 T[j],若相等,则在主串 S 中存在以 i 为起始位置匹配成功的可能性,继续往后比较( j逐步增1 ),直至与T串中最后一个字符相等为止,否则改从S串的下一个字符起重新开始进行下一轮的"匹配",即将串T向后滑动一位,即 i 增1,而 j 退回至0,重新开始新一轮的匹配。
例如:在串S=”abcabcabdabba”中查找T=” abcabd”(我们可以假设从下标0开始):先是比较S[0]和T[0]是否相等,然后比较S[1] 和T[1]是否相等…我们发现一直比较到S[5] 和T[5]才不等。如图一:
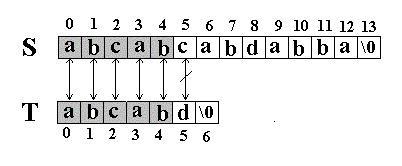
图一

图二
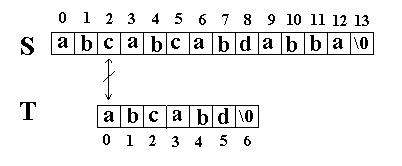
图三
图四
BF 算法最为简单与原始,通常作为对照算法,被用来作正确性验证等目的。
二. KMP匹配算法
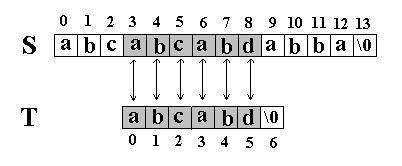
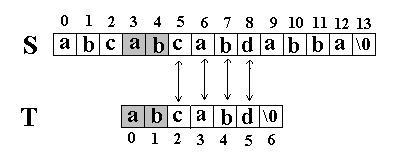
还是相同的例子,在S=”abcabcabdabba”中查找T=”abcabd”,如果使用KMP匹配算法,当第一次搜索到S[5] 和T[5]不等后,S下标不是回溯到1,T下标也不是回溯到开始,而是根据T中T[5]==’d’的模式函数值(next[5]=2,为什么?后面讲),直接比较S[5] 和T[2]是否相等,因为相等,S和T的下标同时增加;因为又相等,S和T的下标又同时增加。。。最终在S中找到了T。如图五:
图五
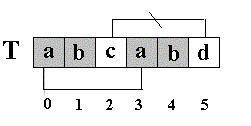
图六
有人可能会问:S[3]和T[0],S[4] 和T[1]是根据next[5]=2间接比较相等,那S[1]和T[0],S[2] 和T[0]之间又是怎么跳过,可以不比较呢?因为S[0]=T[0],S[1]=T[1],S[2]=T[2],而T[0] != T[1], T[1] != T[2],==> S[0] != S[1],S[1] != S[2],所以S[1] != T[0],S[2] != T[0]. 还是从理论上间接比较了。
有人疑问又来了,你分析的是不是特殊轻况啊。
假设S不变,在S中搜索T=“abaabd”呢?答:这种情况,当比较到S[2]和T[2]时,发现不等,就去看next[2]的值,next[2]=-1,意思是S[2]已经和T[0] 间接比较过了,不相等,接下来去比较S[3]和T[0]吧。
假设S不变,在S中搜索T=“abbabd”呢?答:这种情况当比较到S[2]和T[2]时,发现不等,就去看next[2]的值,next[2]=0,意思是S[2]已经和T[2]比较过了,不相等,接下来去比较S[2]和T[0]吧。
假设S=”abaabcabdabba”在S中搜索T=“abaabd”呢?答:这种情况当比较到S[5]和T[5]时,发现不等,就去看next[5]的值,next[5]=2,意思是前面的比较过了,其中,S[5]的前面有两个字符和T的开始两个相等,接下来去比较S[5]和T[2]吧。
总之,有了串的next值,一切搞定。那么,怎么求串的模式函数值next[n]呢?(本文中next值、模式函数值、模式值是一个意思。)
三. 怎么求串的模式值next[n]
(2)next[j]= -1 意义:模式串T中下标为j的字符,如果与首字符相同,且j的前面的1—k个字符与开头的1—k个字符不等(或者相等但T[k]==T[j])(1≤k<j)。
如:T=”abCabCad” 则 next[6]=-1,因T[3]=T[6]
(3)next[j]=k 意义:模式串T中下标为j的字符,如果j的前面k个字符与开头的k个字符相等,且T[j] != T[k] (1≤k<j)。
即T[0]T[1]T[2]。。。T[k-1]==T[j-k]T[j-k+1]T[j-k+2]…T[j-1] ,且T[j] != T[k].(1≤k<j);
(4) next[j]=0 意义:除(1)(2)(3)的其他情况。
|
下标
|
0
|
1
|
2
|
3
|
4
|
|
T
|
a
|
b
|
c
|
a
|
c
|
|
next
|
-1
|
0
|
0
|
-1
|
1
|
|
下标
|
0
|
1
|
2
|
3
|
4
|
|
T
|
a
|
b
|
c
|
a
|
b
|
|
next
|
-1
|
0
|
0
|
-1
|
0
|
|
下标
|
0
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
|
T
|
a
|
b
|
a
|
b
|
c
|
a
|
a
|
b
|
c
|
|
next
|
-1
|
0
|
-1
|
0
|
2
|
-1
|
1
|
0
|
2
|
|
下标
|
0
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
|
T
|
a
|
b
|
C
|
a
|
b
|
C
|
a
|
d
|
|
next
|
-1
|
0
|
0
|
-1
|
0
|
0
|
-1
|
4
|
四. 求串T的模式值next[n]的函数
说了这么多,是不是觉得求串T的模式值next[n]很复杂呢?要叫我写个函数出来,目前来说,我宁愿去登天。好在有现成的函数,当初发明KMP算法,写出这个函数的先辈,令我佩服得六体投地。我等后生小子,理解起来,都要反复琢磨。下面是这个函数:
[code lang=cpp]
void get_nextval(const char *T, int next[])
{
// 求模式串T的next函数值并存入数组 next。
int j = 0, k = -1;
next[0] = -1;
while ( T[j/*+1*/] != '�' )
{
if (k == -1 || T[j] == T[k])
{
++j; ++k;
if (T[j]!=T[k])
next[j] = k;
else
next[j] = next[k];
}// if
else
k = next[k];
}// while
////这里是我加的显示部分
// for(int i=0;i<j;i++)
//{
// cout<<next;
//}
//cout<<endl;
}// get_nextval
另一种写法,也差不多。
void getNext(const char* pattern,int next[])
{
next[0]= -1;
int k=-1,j=0;
while(pattern[j] != '�')
{
if(k!= -1 && pattern[k]!= pattern[j] )
k=next[k];
++j;++k;
if(pattern[k]== pattern[j])
next[j]=next[k];
else
next[j]=k;
}
////这里是我加的显示部分
// for(int i=0;i<j;i++)
//{
// cout<<next;
//}
//cout<<endl;
}
[/code]
下面是KMP模式匹配程序,各位可以用他验证。记得加入上面的函数
[code lang=cpp]
#include <iostream.h>
#include <string.h>
int KMP(const char *Text,const char* Pattern) //const 表示函数内部不会改变这个参数的值。
{
if( !Text||!Pattern|| Pattern[0]=='�' || Text[0]=='�' )//
return -1;//空指针或空串,返回-1。
int len=0;
const char * c=Pattern;
while(*c++!='�')//移动指针比移动下标快。
{
++len;//字符串长度。
}
int *next=new int[len+1];
get_nextval(Pattern,next);//求Pattern的next函数值
int index=0,i=0,j=0;
while(Text!='�' && Pattern[j]!='�' )
{
if(Text== Pattern[j])
{
++i;// 继续比较后继字符
++j;
}
else
{
index += j-next[j];
if(next[j]!=-1)
j=next[j];// 模式串向右移动
else
{
j=0;
++i;
}
}
}//while
delete []next;
if(Pattern[j]=='�')
return index;// 匹配成功
else
return -1;
}
int main() // abCabCad
{
char* text="bababCabCadcaabcaababcbaaaabaaacababcaabc";
char*pattern="adCadCad";
//getNext(pattern,n);
//get_nextval(pattern,n);
cout<<KMP(text,pattern)<<endl;
return 0;
}
[/code]
五.其他表示模式值的方法
上面那种串的模式值表示方法是最优秀的表示方法,从串的模式值我们可以得到很多信息,以下称为第一种表示方法。
第二种表示方法,虽然也定义next[0]= -1,但后面绝不会出现-1,除了next[0],其他模式值next[j]=k(0≤k<j)的意义可以简单看成是:
下标为j的字符的前面最多k个字符与开始的k个字符相同,这里并不要求T[j] != T[k]。
其实next[0]也可以定义为0(后面给出的求串的模式值的函数和串的模式匹配的函数,是next[0]=0的),这样,next[j]=k(0≤k<j)的意义都可以简单看成是:
下标为j的字符的前面最多k个字符与开始的k个字符相同。
第三种表示方法是第一种表示方法的变形,即按第一种方法得到的模式值,每个值分别加1,就得到第三种表示方法。
下面给出几种方法的例子:
|
下标
|
0
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
|
T
|
a
|
b
|
a
|
b
|
c
|
a
|
a
|
b
|
c
|
|
(1) next
|
-1
|
0
|
-1
|
0
|
2
|
-1
|
1
|
0
|
2
|
|
(2) next
|
-1
|
0
|
0
|
1
|
2
|
0
|
1
|
1
|
2
|
|
(3) next
|
0
|
1
|
0
|
1
|
3
|
0
|
2
|
1
|
3
|
|
下标
|
0
|
1
|
2
|
3
|
4
|
|
T
|
a
|
b
|
c
|
A
|
c
|
|
(1)next
|
-1
|
0
|
0
|
-1
|
1
|
|
(2)next
|
-1
|
0
|
0
|
0
|
1
|
|
下标
|
0
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
|
T
|
a
|
d
|
C
|
a
|
d
|
C
|
a
|
d
|
|
(1)next
|
-1
|
0
|
0
|
-1
|
0
|
0
|
-1
|
0
|
|
(2)next
|
-1
|
0
|
0
|
0
|
1
|
2
|
3
|
4
|
对比串的模式值第一种表示方法和第二种表示方法,看表一:
第一种表示方法next[2]= -1,表示T[2]=T[0],且T[2-1] !=T[0]
第二种表示方法next[2]= 0,表示T[2-1] !=T[0],但并不管T[0] 和T[2]相不相等。
第一种表示方法next[3]= 0,表示虽然T[2]=T[0],但T[1] ==T[3]
第二种表示方法next[3]= 1,表示T[2] =T[0],他并不管T[1] 和T[3]相不相等。
第一种表示方法next[5]= -1,表示T[5]=T[0],且T[4] !=T[0],T[3]T[4] !=T[0]T[1],T[2]T[3]T[4] !=T[0]T[1]T[2]
第二种表示方法next[5]= 0,表示T[4] !=T[0],T[3]T[4] !=T[0]T[1] ,T[2]T[3]T[4] !=T[0]T[1]T[2],但并不管T[0] 和T[5]相不相等。换句话说:就算T[5]==’x’,或 T[5]==’y’,T[5]==’9’,也有next[5]= 0 。
从这里我们可以看到:串的模式值第一种表示方法能表示更多的信息,第二种表示方法更单纯,不容易搞错。当然,用第一种表示方法写出的模式匹配函数效率更高。比如说,在串S=“adCadCBdadCadCad 9876543”中匹配串T=“adCadCad”, 用第一种表示方法写出的模式匹配函数,当比较到S[6] != T[6] 时,取next[6]= -1(表三),它可以表示这样许多信息: S[3]S[4]S[5]==T[3]T[4]T[5]==T[0]T[1]T[2],而S[6] != T[6],T[6]==T[3]==T[0],所以S[6] != T[0],接下来比较S[7]和T[0]吧。如果用第二种表示方法写出的模式匹配函数,当比较到S[6] != T[6] 时,取next[6]= 3(表三),它只能表示:S[3]S[4]S[5]== T[3]T[4]T[5]==T[0]T[1]T[2],但不能确定T[6]与T[3]相不相等,所以,接下来比较S[6]和T[3];又不相等,取next[3]= 0,它表示S[3]S[4]S[5]== T[0]T[1]T[2],但不会确定T[3]与T[0]相不相等,即S[6]和T[0] 相不相等,所以接下来比较S[6]和T[0],确定它们不相等,然后才会比较S[7]和T[0]。是不是比用第一种表示方法写出的模式匹配函数多绕了几个弯。
为什么,在讲明第一种表示方法后,还要讲没有第一种表示方法好的第二种表示方法?原因是:最开始,我看严蔚敏的一个讲座,她给出的模式值表示方法是我这里的第二种表示方法。
她说:“next 函数值的含义是:当出现S !=T[j]时,下一次的比较应该在S和T[next[j]] 之间进行。”虽简洁,但不明了,反复几遍也没明白为什么。而她给出的算法求出的模式值是我这里说的第一种表示方法next值,就是前面的get_nextval()函数。匹配算法也是有瑕疵的。
书归正传,下面给出求第二种表示方法表示的模式值的函数,为了从S的任何位置开始匹配T,“当出现S!=T[j]时,下一次的比较应该在S和T[next[j]] 之间进行。”定义next[0]=0 。
[code lang=cpp]
void myget_nextval(const char *T, int next[]) {
// 求模式串T的next函数值(第二种表示方法)并存入数组 next。
int j = 1, k = 0;
next[0] = 0;
while ( T[j] != '�' ) {
if(T[j] == T[k]) {
next[j] = k;
++j; ++k;
} else if(T[j] != T[0]) {
next[j] = k;
++j;
k=0;
} else {
next[j] = k;
++j;
k=1;
}
} //while
for(int i = 0;i < j;i++) {
cout<< next ;
}
cout<<endl;
} // myget_nextval
[/code]
附:KMP算法C语言实现源码
[code lang=cpp]
//KMP算法的实现:(注意在D盘里建个txt.txt文件,里头随便打上一些字符)
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <time.h>
int* GetPrefixValue(char* strPattern, int iPatternLen)
{
int i, j; /* i runs through the string, j counts the hits*/
int* prefix = (int*)malloc(iPatternLen*sizeof(int));
i = 1; j = 0;
prefix[0] = 0;
while(i<iPatternLen)
{
if(strPattern == strPattern[j])
{
prefix = ++j;
}
else
{
j = 0;
prefix = j;
}
i++;
}
return prefix;
}
//返回target串在pattern串中第一次匹配的index
int KMPStringMatch(char* strPattern, int iPatternLen, char* strTarget, int iTargetLen, int* prefix)
{
int i = 0;
int j = 0;
while(i<iPatternLen && j<iTargetLen)
{
if(j==0 || strPattern==strTarget[j])
{
i++; j++;
}
else
{
j = prefix[j];
}
}
free(prefix);
if(j==iTargetLen)
{
return i-j;
}
else
{
return -1;
}
}
int KMP(char* strPattern, char* strTarget)
{
int* prefix = GetPrefixValue(strPattern, strlen(strPattern));
int index = KMPStringMatch(strPattern, strlen(strPattern), strTarget, strlen(strTarget), prefix);
return index;
}
//在文本文件中查找target串出现的行数
int SearchInTxtFile(char* fileName, char* strTarget)
{
FILE* hFile = fopen(fileName, "r");
char str[1024];
int count = 0;
while(fgets(str, 1024, hFile))
{
if(KMP(str, strTarget)!=-1)
{
count++;
}
}
fclose(hFile);
hFile=NULL;
return count;
}
int main()
{
char ch;
char str1[] = "abcabcabctasksb,abTo";
char str2[] = "abc";
double t=clock();
printf("%dn", KMP(str1,str2));
printf("耗时:%f毫秒!n", (clock()-t));
t=clock();
//printf("find %d n", SearchInTxtFile("d:\txt.txt", "NULL"));
printf("find %d n", SearchInTxtFile("d:\txt.txt", "abc"));
printf("耗时:%f毫秒!n", (clock()-t));
scanf("%c", &ch);
return 0;
}
[/code]
KMP算法C语言实现源码下载:点击下载此文件


非常不错,支持博主
很喜欢你这个博客程序。感觉很强大哦
文章很好,滑膜炎官网来过,欢迎回访