常见经典字符串匹配算法简要介绍 & 柔性的字符串匹配pdf下载地址
- 存储安全
- 2011-10-15
- 8561热度
- 1评论
在网络安全的研究中,字符串匹配是一种使用普遍而关键的技术,如杀毒软件、IDS中的特征码匹配、内容过滤等,都需要用到字符串匹配。作为字符串匹配中的一种特殊情况,近似字符串匹配的研究也同样重要。这里对经典的字符串匹配算法与思想进行简要分析和总结。
本文的主要参考了《柔性字符串匹配》一书。不可多得的一部专业书籍,有兴趣者可移步这里下载PDF电子书:柔性字符串匹配下载地址
一 精确字符串匹配
字符串的精确匹配算法中,最著名的有KMP算法和BM算法。下面分别对几种常用的算法进行描述。
1:KMP算法
KMP算法,即Knuth-Morris-Pratt算法,是一种典型的基于前缀的搜索的字符串匹配算法。Kmp算法的搜索思路应该算是比较简单的:模式和文件进行前缀匹配,一旦发现不匹配的现象,则通过一个精心构造的数组索引模式向前滑动的距离。这个算法相对于常规的逐个字符匹配的方法的优越之处在于,它可以通过数组索引,减少匹配的次数,从而提高运行效率。
详细算法介绍参考:KMP算法详解(matrix67原创)
2:Horspool算法
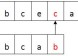
和KMP算法相反,Horspool算法采用的是后缀搜索方法。Horspool算法可以说是BM算法的意见简化版本。在进行后缀匹配的时候,若发现不匹配字符,则需要将模式向右移动。假设文本中对齐模式最后一个字符的元素是字符C,则Horspool算法根据C的不同情况来确定移动的距离。实际上,Horspool算法也就是通过最大安全移动距离来减少匹配的次数,从而提高运行效率的。
算法参考:《算法设计与分析基础》 第二版 清华大学出版社
3:BM算法
BM算法采用的是后缀搜索(Boyer-Moore算法)。BM算法预先计算出三个函数值d1、d2、d3,它们分别对应三种不同的情形。当进行后缀匹配的时候,如果模式最右边的字符和文本中相应的字符比较失败,则算法和Horspool的操作完全一致。当遇到不匹配的字符并非模式最后字符时,则算法有所不同。
算法参考:《算法设计与分析基础》 第二版 清华大学出版社
4:Shift-And算法
这种算法比KMP简单,不过它的特点在于运用了位并行技术,提高程序运行效率。Shift-And算法首先构造一个表,记录字母表中每个字符的位掩码。然后每读取一个文本字符的时候,通过计算公式的运算,获取新的位向量。
二近似字符串匹配
近似字符串匹配主要有四种方法。第一种是动态规划方法,这是最古老,同时也是最灵活的近似匹配算法。第二种是基于自动机公式模拟文本搜索。第三种方式采用位并行方法来模拟其他方法,号称是“最成功”的一种方法。最后则是通过简单的过滤文本中不相关文本时间快速搜索。
1:动态规划算法
动态规划算法是基于“编辑距离”的概念实现近似字符串匹配。通俗地说,编辑距离表示将一个字符串变换成另一个字符串所需要进行的最少的编辑次数。这里的编辑操作包括添加、删除、替换。通过计算编辑距离矩阵,可以得出最佳匹配。
编辑矩阵的初始化和计算是动态规划算法的关键。初始化数值直接决定是全局匹配还是局部匹配,而在计算公式中所采用的增量,则表示了各种操作的权值。
上面公式中,这三种编辑操作的权值都为1,但是实际上可以修改权值以限制各种编辑操作出现的频率。例如,在PI项目中,就采用了不同的权值进行计算。详细描述参考”Network Protocol Analysis using Bioinformatics Algorithms”。
算法描述中提到,为了减少空间复杂度,没有必要保存整个编辑矩阵。但是,貌似如果不保存整个编辑矩阵的话,就很难通过回溯的方法找到最优匹配。
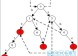
2:基于自动机的算法
关于基于自动机的方法,相关资料比较少,而中文资料则更少。在《柔性字符串匹配》一书中稍微提到的这种方法,但是并没有深入讲解其中的原理和实现步骤。
上面这个状态转换图让人感觉莫名其妙,不知道这个自动机是如何转换的。实际上,这是通过公式计算出来的。
详细介绍请参考:Faster Approximate String Matching
3:位并行算法
实际上,与其说位并行算法是一种近似搜索方法,倒不如说它是一种加速实现的手段。位并行算法是用来模拟经典算法的。在搜索中,通过并行模拟,可以加快经典算法的运行速度。位并行算法非常适合模式串比较短的情况。
位并行实际上利用了计算机的并行性原理,将若干不同的值打包到一个长度为w的计算机字中,这样就可以利用一次操作或运算来实现原本需要若干次操作或运算才能完成的功能。
参考:《用位并行法进行过滤的中文近似串匹配算法》
4:文本快速过滤算法
过 滤算法是基于这种思想:判断文中某个位置的字串和模式串不匹配,可能比判断而这相匹配更容易。所以过滤算法的思路为:通过过滤算法过滤文本中不能产生成功 匹配的区域,然后结合非过滤文本搜索算法,最终实现快速字符串匹配。当错误水平比较低时,文本过滤算法的运行效果很好,否则就很差。
过滤算法比较多,当字母表不是太小的时候,PEX方法运行效果最好。当字母表很小的时候,ABNDM算法比较好。
5 总结
以 上讨论了四种近似字符串匹配方法的主要思路。实际上,我们可以看到,字符串匹配方法的关键计算编辑距离。动态规划直接计算编辑距离矩阵,而自动机方法则以 另一种方式表示了文本输入后的编辑距离向量。位并行算法主要是利用计算机的并行性,模拟经典近似匹配算法,加快运算速度。文本过滤算法则通过过滤不可能成 功匹配的文本,然后结合经典近似匹配算法实现快速字符串匹配。



不懂这个东西,看了头脑一片空白