正确区分开发与生产模式:移除调试代码的几种方法
- 前端开发
- 2022-12-11
- 1372热度
- 0评论
摘要
不要将开发模式的调试代码带到生产环境,否则你的实现方式可能是存在安全隐患的。本文主要介绍了可能给生产环境提供调试“后门”的方式,以及基于环境变量、魔术常量、以及`strip-loader`构建工具插件实现对非当前环境的调试代码进行清理的几种方法与原理,并分析了他们各自的优缺点。

切记:不要将开发模式的调试代码带到生产环境,否则你的实现方式可能是存在安全隐患的。
在前端开发过程中,针对不同的运行环境执行不同的代码逻辑是一种常见需求。
例如:
- 本地开发模式下,为了方便调试分析,而添加了 console 日志打印、调试工具库、局部业务逻辑验证等调试代码。
- 在构建产物上区分不同的环境,如本地开发(dev)、测试(test)、仿真(uat)、生产(prod)等。在各环境中因为不同的目的而执行不同的代码逻辑、加载不同的依赖文件。
- more...
无论是调试代码还是非当前环境的代码逻辑和依赖文件,假若在构建时未作任何处理,在构建产物上都有一定的负面的影响。大量的调试代码可能会引起性能方面的问题,也会让生产环境的业务逻辑更容易被外部人员窥探与调试;因为引用了不必要的依赖(库),构建产物的尺寸也会变大;甚至可能会因为调试模式下未及时移除的敏感信息被发布至生产,带来敏感信息泄漏的风险。
综上所述,在构建输出时,将非必要的代码移除成为了一种必要的需求。
1 生产环境中的那些“后门”逻辑
1.1 主动给生产模式留一些“后门”
在某些情况下,你可能会故意将调试代码带至生产,允许根据特定的条件触发。以便于需要时可以直接在生产上调试。所以你区分不同环境的方式可能是这样的:
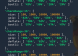
// 示例:通过 url 参数启动调试逻辑
const urlParams = getUrlParams();
if (urlParams._mode_ === 'local_dev') {
// 调试逻辑
user.pwd = 'xxx';
}
通过 URL 参数、某些部位快速点击N次(例如常见的Android系统中连续七次点击开启调试模式的方式)等特定条件触发调逻辑,这种方法无疑是简单易操作的,在快速分析定位生产问题时能起到许多帮助。但这里提醒的是,该方法虽然简洁高效,但需特别注意,请勿过量食用。因为可能有大量安全从业者在关注着你的线上产品,稍微花点时间分析一下很容易看出端倪。调试代码就像一个后门程序,如果逻辑过于强大、包含了敏感信息则后果也是严重的。
需要注意的是,即使你没有主动设置“后门开关”,但只要发布至生产的产物中包含了调试代码,它仍然是一种后门逻辑,因为只需要在调试过程中稍加拦截与修改条件即可触发它们。而且由于不是你有意为之,带来的隐患可能更为严重。
分析一下你的项目中涉及到调试的逻辑,是否存在此类问题呢?实际上这种调试代码带至生产的方式,是我见过较多的现象。
1.2 切勿将 SoureMap 发布至生产环境可访问
开发、测试环境下开启 sourceMap,可以很方便的基于源代码进行调试。但请注意切勿将调试模式的 sourceMap 文件发布至生产环境中。基于 sourceMap 文件可以将项目的源码进行还原,带来源码泄漏的风险。
例如借助 Chrome 调试工具,可以基于 sourceMap 导出源码;也可以基于 shuji、restore-source-tree 等这样的一些工具,基于 .map 文件一键还原项目源码。
此外,即使是不包含 sourceContent 的生产模式的 sourceMap,也会给安全从业者调试你的源码带去方便。
比较推荐的做法是,将生产模式下生成的 .map 文件上传至 Sentry 等异常收集平台,然后将 .map 文件进行清理。或者将生产模式下生成的 .map 文件移动并发布至仅内网可访问的位置,生产模式仅返回空文件。
2 基于 process.env 区分开发与生产模式
如果你关注过 React、Vue 等流行库的源码,可能会注意到对 process.env.NODE_ENV 来区分开发与生产的方式。它一般是这样的:
if (process.env.NODE_ENV === 'production') {
prod(); // 执行生产模式逻辑
} else {
dev(); // 执行开发模式逻辑
}
在构建输出的产物中,它实际上会被编译替换为这样:
if ('production' === 'production') {
prod(); // 执行生产模式逻辑
} else {
dev(); // 执行开发模式逻辑
}
可以看到 process.env.NODE_ENV 被构建工具替换处理为了常量字符串。'production' === 'production' 这种表达式在压缩工具静态分析时可以识别为 true 或 false,进一步的优化过程中,则可以将为 false 部分的逻辑移除,压缩优化工具处理完毕后的理想结果会是这样的:
prod();
可以看到,利用 process.env 的方式,只需要在构建时指定不同的环境变量值,即可在最终的构建产物上移除不必要的逻辑。
但是这种方法具有一定的局限性,对于支持 node.js 的运行环境,如 Node.js 应开发、Electron 应用开发等场景下,process.env 就不能如此替换了。那么其效果会会退为“后门模式”,从而带来生产安全隐患。
3 基于魔术常量区分开发与生产环境
在 webpack、vite 等构建工具中,都可以基于插件注入魔术常量。
webpack 中定义魔术常量:
module.export = {
plugins: [
new webpack.DefinePlugin({
LZWME_DEV: process.env.NOE_ENV === 'development',
LZWME_PROD: process.env.NOE_ENV === 'production',
LZWME_UAT: process.env.BUILD_ENV === 'uat',
})
]
}
vite 中定义魔术常量:
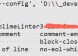
import { defineConfig, loadEnv } from 'vite';
export default defineConfig(({ command, mode }) => {
const env = loadEnv(mode, process.cwd(), '');
return {
define: {
LZWME_DEV: env.NOE_ENV === 'development',
LZWME_PROD: env.NOE_ENV === 'production',
LZWME_UAT: env.BUILD_ENV === 'uat',
},
};
});
魔术常量可以直接在项目中当作全局常量使用。示例:
// global.d.ts 中声明类型
/** 本地开发环境 */
declare const LZWME_DEV: boolean;
/** UAT 环境 */
declare const LZWME_UAT: boolean;
/** 生产环境 */
declare const LZWME_PROD: boolean;
应用逻辑中使用魔术常量:
if (LZWME_DEV) {
await import('./xxx.dev');
localDev();
}
if (LZWME_UAT) {
uat();
}
if (LZWME_PROD) {
prod();
}
在编译产物中,上面的应用逻辑可能会被编译为这样:
if (false) {
await import('./xxx.dev');
localDev();
}
if (true) {
uat();
}
if (true) {
prod();
}
进一步的,在压缩工具优化后,构建终产物中的逻辑会是这样的:
uat();
prod();
魔术常量的方式可以很好的处理不同环境下的调试代码清理问题,但是仍然具有一定的局限性。例如仅希望在特定环境下存在的内容,如非 Javascript 块逻辑的大段代码、Top import 方式引入的依赖等。他们都是没法用条件语句做判断的。
4 strip-loader:基于构建工具插件区分开发与生产模式
假设存在如下代码:
import { devData } from './dev-data';
export class LzwmeAbc {
init() {
if (LZWME_DEV) this.data = this.random();
// more...
}
random() {
const data = [];
// more...
return data.concat(devData);
}
// more...
}
可以看到,在非 LZWME_DEV 环境下,random 方法虽然不会执行,但是不会被清理,./dev-data 文件也不会得到清理,从而将测试数据与处理逻辑泄漏了出去。
基于构建工具开发插件,可以按照配置规则对匹配到的特定内容作清理移除,从而实现基于魔术常量的方法一样的效果。
假设我们设定一个规则:将包含注释内容 /* devblock:start */ 和 /* devblock:end */之间的代码,在非开发模式下移出。上面的代码可修改为这样:
/* devblock:start */
import { devData } from './dev-data';
/* devblock:end */
export class LzwmeAbc {
init() {
if (LZWME_DEV) this.data = this.random();
// more...
}
/* devblock:start */
random() {
const data = [];
// more...
return data.concat(devData);
}
/* devblock:end */
// more...
}
构建为非开发模式时,清理后的内容会是这样的:
export class LzwmeAbc {
init() {
// more...
}
// more...
}
strip-loader 即是这样的一款插件,它参考了社区常见的此类方案,并做了一些扩展。其 gayhub 地址为: https://github.com/lzwme/strip-loader,有兴趣的同学可以关注一下。
strip-loader 支持 webpack 和 rollup 构建工具。
webpack 配置示例:
module.exports = {
module: {
rules: [
{
// test: /\.(t|j)sx?$/,
test: /\.(css|scss|less|jsx?|tsx?)$/,
enforce: 'pre',
exclude: /node_modules/,
use: [
{
loader: require.resolve('@lzwme/strip-loader'),
options: {
disabled: process.env.NODE_ENV === 'development',
blocks: [{
start: 'devblock:start',
end: 'devblock:end',
prefix: '/*',
end: '*/',
},
// 非 uat 环境下,清理 uat 模式的特定代码
process.env.NODE_ENV !== 'uat' ? {
start: 'uat:start',
end: 'uat:end',
} : null].filter(Boolean),
},
},
],
},
];
}
}
rollup 插件配置示例:
import { rollupStripPlugin } from '@lzwme/strip-loader';
export default {
input: 'src/index.js',
output: {
dir: 'output',
format: 'cjs'
},
plugins: [
rollupStripPlugin({
disabled: process.env.NODE_ENV !== 'production',
includes: '**/*.(js|jsx|ts|tsx)',
exlude: 'tests/**/*',
debug: false,
blocks: [{
start: 'devblock:start',
end: 'devblock:end',
},
// 非 uat 环境下,清理 uat 模式的特定代码
process.env.BUILD_ENV !== 'uat' ? {
start: 'uat:start',
end: 'uat:end',
} : null].filter(Boolean),
}),
]
};
由于 vite 构建非开发模式下使用 rollup 构建,故也可以直接配置该插件。
strip-loader 方案虽然简单,但也存在一些缺点。strip-loader 通过简单的关键字匹配方式对源码预处理清理,从而实现按条件移出调试代码的目的。但是对于大段的代码逻辑处理,在修改或重构时需要特别注意开始与结束注释字符的处理匹配性。我们就曾遇到类似这样的场景:
- 某个核心公共文件存在多个
devblock代码块,用于本地开发时开启不同的调试能力或辅助功能。 - 某次的代码合并处理冲突时,不小心将一段
devblock:end部分移除了。代码语法仍然没有任何问题,可正常编译。 - 上线测试时出现了表现怪异的现象。分析了许久才发现问题所在,由于匹配范围扩大,更多的常规逻辑代码也被清理了。
我们推荐结合魔术常量和 strip-loader的方式按需选择实现方案。
5 小结
本文主要介绍了可能给生产环境提供调试“后门”的方式,以及基于环境变量、魔术常量、以及strip-loader构建工具插件实现对非当前环境的调试代码进行清理的几种方法与原理,并分析了他们各自的优缺点。
在实际的开发实践过程中,我们主要结合 魔术常量 和 strip-loader,对块级代码使用 魔术常量 方式,条件语句不能支持的场景则使用 strip-loader。禁止使用“后门”的方式将不必要的调试代码带至生产环境。
对于区分开发与生产模式的逻辑实现,你们是怎么做的呢?